中国のAIスタートアップ企業「深度求索(DeepSeek)」が開発した大規模言語モデル(LLM)「DeepSeek-V3」と「DeepSeek-R1」が、Metaをはじめとする米国AI企業に激震を与えています。
Metaの匿名従業員が職場匿名フォーラム「TeamBlind」で明かした内部状況によれば、同社の生成AI部門は「パニックモード」に陥り、DeepSeekの技術を必死に解析・模倣しているとのこと。
その背景には、低コストで高性能なモデル開発と、組織構造の根本的な問題が浮き彫りになりました。
正对着DeepSeek狂抄?Meta被曝整个AI部门深陷恐慌
DeepSeekの圧倒的コスト効率と技術革新
550万ドル vs. 5億ドル
DeepSeek-V3(2024年12月公開)は、6710億パラメータの混合専門家(MoE)アーキテクチャを採用し、MetaのLlama 3.1-405Bを性能で凌駕しています。
訓練コストはわずか550万ドル(約2.8M H800 GPU時間)で、MetaのLlama 3シリーズの計算リソース(3930万H100 GPU時間)の15分の1、OpenAIのGPT-4oの20分の1以下という驚異的な効率性を実現しました。
Metaの従業員は「1人の管理職の年収でDeepSeek-V3の総訓練コストを超えてまうで!」と指摘し、高コスト体質の矛盾を露呈しています。
技術的ブレイクスルー
DeepSeek-R1(2025年1月公開)は、人間の注釈データを一切使用せず、大規模強化学習(RL)のみで訓練された初のオープンソースモデルです。
数学・論理タスクではOpenAIの最新モデル「o1」と同等性能を達成し、APIコストはo1の10分の1以下という競争力を持ちます。
さらに、MoEアーキテクチャに加え、FP8混合精度訓練や多トークン予測といった独自技術で、推論速度と効率を最大化しています。
- MoEアーキテクチャ
「MoE」とは「Mixture of Experts(専門家の組み合わせ)」の略。この技術は、大量の「専門家(モデルの一部)」の中から必要なものだけを使う仕組み。すべての専門家を同時に使わないため、計算を効率化できる。 - FP8混合精度訓練
通常、AIを訓練するときは「数値の精度」を高く保つ必要があるが、計算コストが大きくなる。FP8は「8ビットの小さな数値」で計算することで、計算を軽くしながら性能を保つ技術。混合精度というのは、必要な部分では高精度(大きい数値)を使い、他の部分では低精度(小さい数値)を使うことで効率化を図る方法。 - 多トークン予測
通常、AIは1回の処理で1つの単語(トークン)を予測するが、この技術では1回で複数の単語を予測する。これにより、処理速度が大幅に上がる。
まとめると、「必要な計算だけを効率よく行い、軽い計算方法(FP8)を使いながら、一度に複数の答えを出す」という工夫を組み合わせることで、AIがより速く、より効率的に動けるようになっているんですね。うーん、よく分からないけど、なんかすごそう。
大手AI研究室は混乱状態
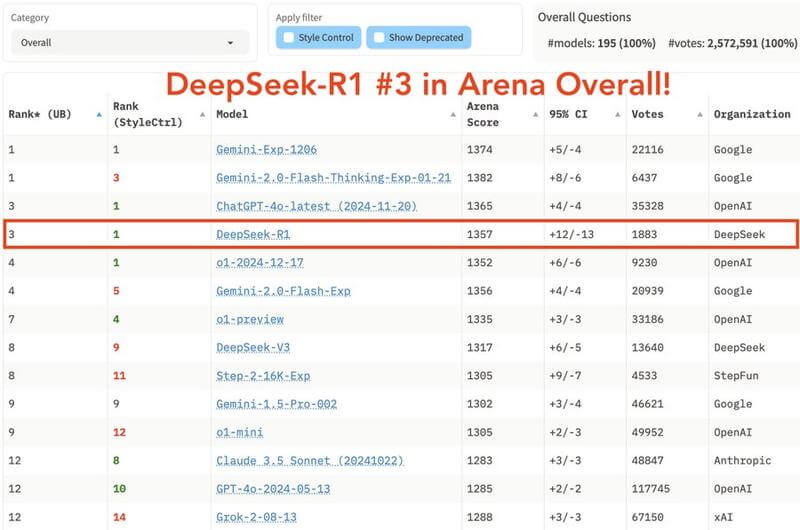
DeepSeek-R1 が LMarena ランキングでトップ 3 に躍進
- OpenAI O1推論モデルに匹敵しながら、コスト効率とオープンウェイトは20倍優れています。
- 技術分野で1位:難しいプロンプト、コーディング、数学
Metaの「パニック」が暴露した組織の脆弱性
肥大化したAI部門の非効率
Metaの生成AI部門は当初、「小規模でエンジニアリング重視」のチームとして設計されました。しかし、複数の利害関係者が参入し、組織が膨張した結果、意思決定が遅延し、コストが急増しています。
匿名従業員は「数十人の高給管理職が存在し、550万ドルの訓練費すら個々の年収に及ばない」と内部批判を明かしています。
技術的逆行の衝撃
DeepSeekのオープンソース戦略により、Metaが中国企業の技術を逆向きエンジニアリングする事態が発生しました。
従来は「米国が技術を輸出する」構図が逆転し、米国企業が中国モデルを解析する新たな競争構造が生まれています。
業界全体への波及効果
米国AI企業の危機感
DeepSeekの成功は、MetaだけでなくGoogleやAnthropicにも影響を与えています。UCバークレーのAlex Dimakis教授は「DeepSeekは技術的に先行しており、米国企業は追いつく必要がある」と指摘しています。
Andrej Karpathy Praises DeepSeek V3’s Frontier LLM, Trained on a $6M Budget
さらに、DeepSeekの低コスト戦略は「AI開発に巨額投資が必要」という前提を崩し、米国の国家プロジェクト(例:トランプ政権の5000億ドル規模「スターゲート計画」)の妥当性にも疑問を投げかけました。
SoftBankとOpenAIが主導するAIインフラ計画「スターゲイト」がトランプ大統領から発表。投資額は4年間で5000億ドル(日本円で約65兆円)
オープンソース競争の矛盾
DeepSeekとMeta(Llama)はいずれもオープンソースモデルを推進しますが、収益化の難しさが共通課題です。ユーザーからは「オープンモデルでは儲からないのに、なぜ過剰な競争を続けるのか」との声も上がっています。
AI業界では長期的戦略としてオープンソースモデルを推進する動きが加速しています。主な利点は以下の4点に集約されます。
- エコシステム拡大 - 開発者参加による市場シェア拡大と将来収益基盤の形成
- 技術革新促進 - 多様な知見を活用した開発スピードの向上
- 信頼構築 - 透明性確保によるブランド価値の向上
- 収益源創出 - 無料モデルを起点とした有償サービス展開(サポート/クラウドソリューション等)
短期的利益より、市場主導権獲得と持続的成長を志向する戦略的アプローチと言えるでしょう。
DeepSeek は単なる「サイド プロジェクト」であり、主な業務は大型モデルの作成ではまったくないことを明らかにする人もいます。
今後の焦点|技術革新 vs. 組織改革
Metaの混乱は、単なる技術格差ではなく、大企業の官僚体質がイノベーションを阻害する構造的問題を露呈しました。一方、DeepSeekの成功要因は以下の点に集約されます。
- アルゴリズム最適化(例:通信効率化、負荷分散戦略)
- データ選別と効率的な訓練プロセス(14.8兆トークンの高品質データ使用)
- オープンソース戦略による開発者コミュニティの活用(Hugging Faceでのダウンロード数爆発)
今後の争点は、MetaがLlama 4で反撃できるか、そしてDeepSeekが倫理的課題(例:ChatGPT出力の訓練データ使用疑惑)をどう克服するかにありそうです。
中国AIの台頭が問いかける「技術民主化」の未来
DeepSeekの躍進は、AI開発の「地政学的シフト」を象徴します。従来の「GPUと資金力が全て」というパラダイムが崩れ、アルゴリズム革新と組織効率が勝敗を分ける時代が到来しました。Metaのパニックは、技術競争の新たなルールを告げる警鐘と言えるでしょう。
一方で、オープンソースの倫理や持続可能性への問いは残ります。AIの未来は、単なる性能競争ではなく、技術の民主化と社会的責任のバランスにかかっているのです。
OpenAIの最新モデル「o3-mini」の無料ユーザー解放もDeepSeekのおかげかも?
事実
中国企業(DeepSeek)が米国企業(openAI)にひざまずいて最新モデルであるo3-miniをユーザーに無料で提供するよう強制しているのは面白いことだ。
同意する?
追記(2025年1月25日):マーク・ザッカーバーグ「MetaのLlama 4は、2025年に主要なAIモデルになるッス」
マーク・ザッカーバーグが本気を出してきたっぽい。
マーク・ザッカーバーグは、MetaのLlama 4が2025年に主要なAIモデルになると述べ、マンハッタンの大部分をカバーするほどの2GW以上のデータセンターを建設しており、今年は1GWのコンピューティングと130万のGPUがオンラインになる予定だ。
Mark Zuckerberg says Meta's Llama 4 will become the leading AI model in 2025 and they are building a 2GW+ data center so large it would cover much of Manhattan, with 1GW of compute and 1.3 million GPUs coming online this year pic.twitter.com/03jp85CEvX
— Tsarathustra (@tsarnick) January 24, 2025