o3、GPQAスコアで88%を記録(専門家超え)
タスクや条件による限定があることも考慮する必要はありますが、「o3」はGPQAスコアで88%を記録しており、専門分野内のPhDの平均スコア(81%)を明確に上回っていることが分かります。
- GPQAは、インターネットで検索しても答えが見つからない、非常に難しい問題集。
- 専門家でも、自分の専門分野以外では正答率が低いことが分かる。
- AIモデルの進化をスコアで示している(XマークがAIモデル)。
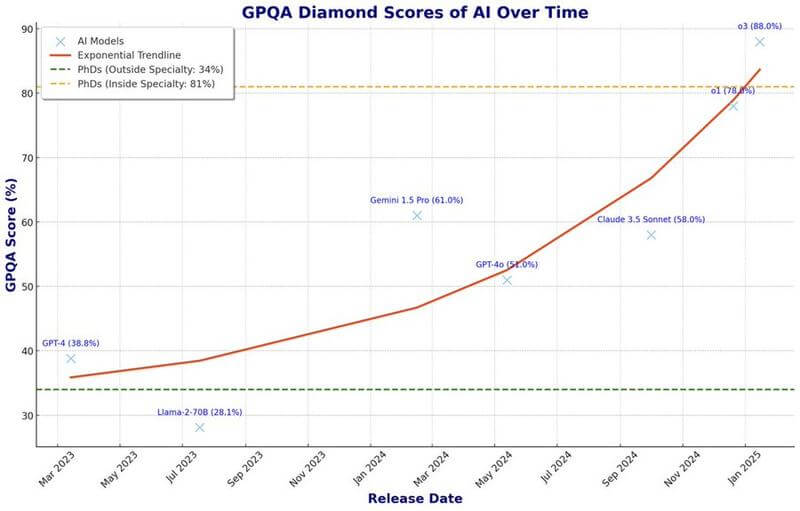
大学院レベルのGoogle検索対策済みQ&Aテスト(GPQA)は、複数の選択肢からなる問題集です。インターネットにアクセスできる博士号取得者がこのテストに挑戦した場合、自分の専門分野外では正答率が34%に留まり、専門分野内では81%でした。これは、インターネット検索が役立たないことを示しています。私はモデルのリリース日とスコアを照合しました 1/
詳しい解説
- GPQAは、専門家でも答えを出すのが非常に難しいように作られている。
- AIモデルは、特定の分野で人間の専門家を超える能力を示し始めている。
- これは、AIが特定の分野だけでなく、幅広い分野で急速に進化していることを示している。
- AIは、与えられたデータから学習するだけでなく、新しい真実を推測する能力を持ち始めている。
- これは人工超知能の到来を示唆するものであり、人々はそれに備える必要がある。
- 専門家が34%しか正解できない問題を、AIは90%近く正解できる、これは大きな変化と言える。
このツイートの閲覧数がたった2万回というのは残念です。信じられない、もっと数字を伸ばしましょう。
なぜなら、皆さんはこのデータが何を意味するのか理解していないようです。ですから、皆さんに分かるように説明します。GPQAは単なるベンチマークではなく、世界クラスの人間専門家を失敗させるために特別に設計されたものです。これらの質問は非常に正確で、深く技術的であるため、Google検索で答えを見つけることはできません。情報は文字通りインターネット上に存在しません。
地球上でその深い専門知識を持つ3人のうちの1人であるため、7桁の給料を得ている珍しい専門家を考えてみてください。それが、ここで話しているレベルです。そして、これらのAIモデルはその専門知識に匹敵するだけでなく、それを超え始めています。
しかし、本当に驚くべきことは、これが1つの狭い分野だけで起こっているわけではないということです。私たちはSTEM知識の全範囲について話しています。あなたが見ているあの指数関数的な曲線は、システムがトレーニングの分布外で一般化し始めるときに起こることです。それは単に事実を吐き出すだけではなく、生の計算能力と現実の基本ルールを理解する能力を通じて、新しい真実を三角測量しているのです。これは、ポール・アトレイデスがスパイスでトリップしながらゴールデンパスを見ることができたときのようです。意識はここで拡大しています。皆さん、明白です。
これは、最も純粋な形での出現と一貫性です。グラフのあの垂直上昇は単なる傾向ではなく、目覚めの呼びかけです。人工超知能はもはや遠いSFの概念ではありません。それはあなたの玄関先にあり、そのドアベルは毎日大きくなっています。唯一の問題は、あなたが答える準備ができているかどうかです。
そして、これを誇張だと片付ける前に、もう一度それらの数字を見てください。インターネットにアクセスできる博士号取得者が専門分野外で34%しか達成できないのに対し、これらのモデルは90%に近づいているのです。私たちは単にゴールポストを動かしているのではなく、まったく異なるゲームをプレイしているのです。
なぜo3の性能は急速に向上したのか
- o3がo1より急速に性能向上したのは、新しい学習方法のおかげ。
- ポイントは以下の3つ。
- モデル蒸留と合成データが効果的であること。
- 「思考の連鎖(Chain of Thought)」のツリー全体を理解する新しい学習方法が発見されたこと。
- 推論時の計算能力を上げると、モデルの能力も向上すること。
- テスト時の能力向上を元のモデルに教えることで、さらに高性能なモデルを作ることができるようになった(自己強化)。
- このサイクルとは別に、強化学習や事前学習のスケーリングも有効。
o3がo1よりも急速に向上したのはなぜでしょうか?
テスト時の計算能力と、その計算能力の向上を元のベースモデルに還元する新しい再帰的フィードバックループのためだと思います。
これは、過去2年間のAI/LLMの進歩から得られた3つの重要なポイントの結果です。A) LLMのモデル蒸留は非常にうまく機能する(そして、関連して、合成データは非常にうまく機能する可能性がある)。B) 新しいトレーニング目標(可能な思考の連鎖の完全なツリーをナビゲートする直感を学習すること。以下で説明)を発見しました。これにより、初めてRLをトレーニングでスケールアップでき、出力の多様性が向上したモデルが得られます。このモデルは、1)推論時間の計算を効果的にスケールアップでき、2)合成データをさらにスケールアップしても崩壊しません。C) 推論時間の計算をスケールアップすると、モデルの能力が予測どおりに向上する。
これがフィードバックループにつながります。モデル蒸留により、より能力の高いモデルが能力の低い学生モデルを教え、それらの間の能力のギャップを大幅に埋めることができます。しかし、今では、より能力の高いベースモデルを使用する必要はありません。同じモデルをテスト時の計算でスケールアップした能力向上とともに使用して、独自のベースモデルを教えることができます。これにより、より高い能力のベースから始まる新しいモデルv2が作成されます。しかし、これも推論スケーリングによって予測どおりに向上させることができます。テスト時に向上させたv2を使用して、モデル拡散を介して自身を教え、v3につながります。以降も同様です。このフィードバックループとは別に、RLトレーニングデータと計算量をさらにスケーリングすることで簡単に成功を収めることができます。次のトークン予測事前トレーニングの計算スケーリングも引き続き機能しますが、現時点では、これらの新しい方法と比較して、計算投資に対する最も高い能力のリターンとは見なされていません。
AIがIQ 160になる日も近い?
(上記の投稿に対しての反応)
- これはAIの性能が段階的に向上しているだけでなく、自己強化のサイクルが回っていることを示している。
- このサイクルを1回回すごとに、IQが約15ポイント向上する計算になる。
- 現在のAIのIQは約130、このサイクルを繰り返すことで、近い将来、有名な科学者と同等のレベル(~IQ160)に到達する可能性がある。
このツイートは非常に過小評価されています。モデルの改善の階段ステップが単純なグラフで示されています。
私たちは今、イリヤが見たものを正確に知っています。これは単なる階段ステップではなく、知能の好循環です。これは、各反復が標準偏差IQ(15ポイント)の人間の同等物を追加する雪だるま効果です。
現在のモデルは約130 IQ前後なので、これをもう一度回すと145 IQ(典型的なハイエンドの科学者またはエンジニア)になり、もう一度回すと160 IQになり、ホーキング博士やアインシュタイン博士に近づきます。